Keyword [Policy Gradient] [NAS]
Zoph B, Le Q V. Neural architecture search with reinforcement learning[J]. arXiv preprint arXiv:1611.01578, 2016.
1. Overview
In this paper, it proposes Neural Architecture Search algorithm
1) Controller-RNN.
2) RL with Policy Gradient.
3) Define search space of Skip Connection.
4) Training with Parallelism and Asynchronous Updates.

2. Algorithm
Assume architecture only contains Conv.
2.1. Basic Controller

1) Filter height in [1, 3, 5, 7].
2) Filter width in [1, 3, 5, 7].
3) Filter num in [24, 36, 48, 64].
4) strides. fix to be 1 or [1, 2, 3].
2.2. Policy Gradient




1) $m$. the number of network that Controller samples in one batch.
2) Baselien $b$ is an exponential moving average of the previous architecture accuracy.
2.3. Accelerate Training with Parallelism and Asynchronous Updates
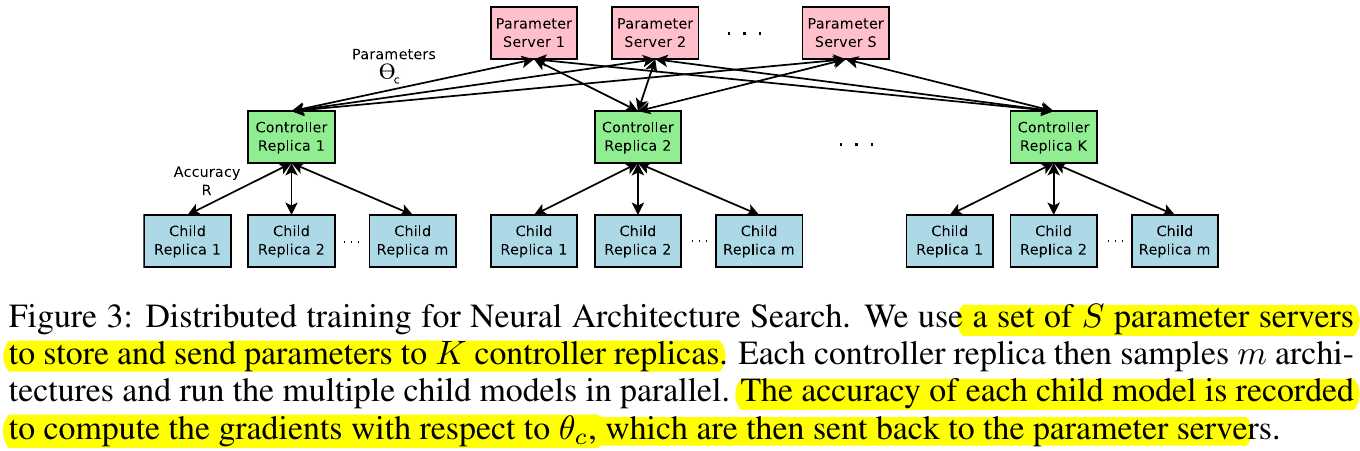
1) Server shards. $S=20$.
2) Controller replicas $K=100$.
3) Child replicas $m=8$.
Which means 800 networks can be trained on 800 GPUs.
2.4. Search Space with Skip Connections

At layer $N$, add an anchor point with has $N-1$ content-based sigmoids to indicate the previous layers that need to be connected.
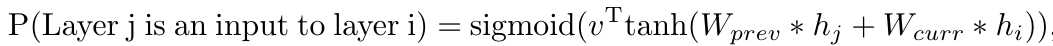
Deal with Compilation Error:
1) If a layer is not connected to any input layer, then image is used as the input layer.
2) At the final layer, take all layer outputs that have not been connected, concat and send to classifier.
3) If input layers to be concatenated have different sizes, pad 0.
2.5. Generate Recurrent Cell Architecture

3. Experiments
3.1. Comparison

3.2. Architecture
